![]()
The Realest Study Materials UiPath-SAIv1 Dumps Updated Dec 02, 2025
LATEST UiPath-SAIv1 Exam Practice Material
NEW QUESTION # 107
What is one of the purposes of the Config file in the UiPath Document Understanding Template?
- A. It defines the input document types and formats supported by the template.
- B. It contains the configuration settings for the UiPath Robot and Orchestrator integration.
- C. It stores the API keys and authentication credentials for accessing external services.
- D. It specifies the output file path and format for the processed documents.
Answer: C
Explanation:
The Config file in the UiPath Document Understanding Template is a JSON file that contains various parameters and values that control the behavior and functionality of the template. One of the purposes of the Config file is to store the API keys and authentication credentials for accessing external services, such as the Document Understanding API, the Computer Vision API, the Form Recognizer API, and the Text Analysis API. These services are used by the template to perform document classification, data extraction, and data validation tasks. The Config file also allows the user to customize the template according to their needs, such as enabling or disabling human-in-the-loop validation, setting the retry mechanism, defining the custom success logic, and specifying the taxonomy of document types.
References: Document Understanding Process: Studio Template, Automation Suite - Document Understanding configuration file
NEW QUESTION # 108
Which of the following extractors can be used for Data Extraction Scope activity?
- A. Intelligent Form Extractor, Machine Learning Extractor. Logic Extractor, and Regex Based Extractor.
- B. Full Extractor. Machine Learning Extractor, Intelligent Form Extractor, and Regex Based Extractor.
C Form Extractor Incremental Extractor Machine Learning Extractor and Intelligent Form Extractor - C. Regex Based Extractor. Form Extractor. Intelligent Form Extractor, and Machine Learning Extractor.
Answer: C
NEW QUESTION # 109
What is the order of steps for automatically retraining and deploying a Document Understanding ML Model in Al Center with data from Document Validation Action?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.
Answer:
Explanation:
Explanation: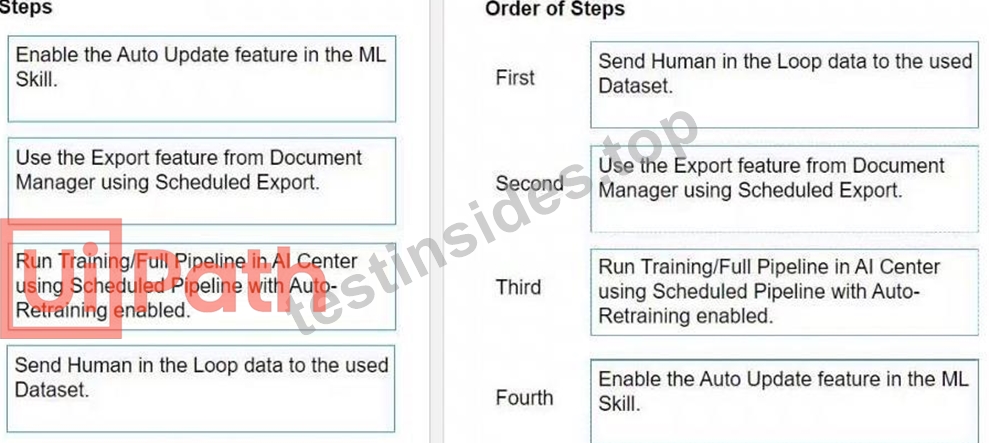
To automatically retrain and deploy a Document Understanding Machine Learning (ML) Model in AI Center with data from the Document Validation Action, the steps should be followed in this order:
* Send Human in the Loop data to the used Dataset.
* This step involves sending the data that has been validated and corrected by human reviewers to the dataset. This data will be used for training the ML model.
* Use the Export feature from Document Manager using Scheduled Export.
* After the data is reviewed and validated, it needs to be exported from the Document Manager.
Scheduled Export automates this process, ensuring the dataset in AI Center is regularly updated with new data.
* Run Training/Full Pipeline in AI Center using Scheduled Pipeline with Auto-Retraining enabled.
* With the updated data in the dataset, the next step is to run the training or the full pipeline. The use of Scheduled Pipeline with Auto-Retraining ensures that the ML model is automatically retrained with the latest data.
* Enable the Auto Update feature in the ML Skill.
* Finally, enabling the Auto Update feature in the ML Skill ensures that the newly trained model is automatically deployed, making the improved model available for document understanding tasks.
Following these steps in the specified order allows for a streamlined process of continuously improving the ML model based on human-validated data, ensuring better accuracy and efficiency in document understanding tasks over time.
NEW QUESTION # 110
How do partially labeled messages impact label predictions in UiPath Communications Mining?
- A. They reduce label bias.
- B. They improve label precision.
- C. They enhance label recall.
- D. They negatively affect model performance.
Answer: D
Explanation:
Partially labeled messages in UiPath Communications Mining can negatively impact model performance because incomplete or inconsistent labeling creates ambiguity for the model during training. This leads to the model receiving conflicting signals, which hampers its ability to generalize well across the dataset, resulting in reduced precision and recall in predictions. Proper and complete labeling is critical to ensure the model learns accurately from the data
NEW QUESTION # 111
How has UiPath improved the experience for handling failed queue transactions in the 2023.10 release?
- A. Recording and storing failed queue transactions for debugging purposes.
- B. Enhancing the logging capabilities to provide more detailed insights into each transaction.
- C. Implementing a sophisticated automatic retry mechanism to handle failed transactions without manual intervention.
- D. Introducing real-time error alerts to notify users immediately when a queue transaction fails.
Answer: A
Explanation:
In the UiPath 2023.10 release, a key improvement introduced was the ability to record and store failed queue transactions for debugging purposes. This feature helps users by capturing the failure details and making them accessible directly in Orchestrator. The recording of failed transactions is enabled at the process level, within the Video section of the Job recording settings. It is intended to facilitate easier troubleshooting of failed automations by providing insights into the moments leading to the failure, which can be reviewed later for debugging
NEW QUESTION # 112
How do you load a taxonomy from a given non-default location text file into a variable?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.
Answer:
Explanation:
Explanation:
to load a taxonomy from a given non-default location text file into a variable, the order of steps should be as follows:
* Create a new variable of type 'DocumentTaxonomy' called 'documentTaxonomy', then create a new string variable called 'taxonomyPath'.
* This step involves setting up the necessary variables that will be used in the process. The
'documentTaxonomy' variable will hold the deserialized taxonomy object, and 'taxonomyPath' will store the path to the taxonomy file.
* Using an Assign activity, assign the given non-default taxonomy text file path to the most recent variable created.
* Here you will assign the path of the taxonomy file to the 'taxonomyPath' variable.
* Use the Read Text File activity on the 'taxonomyPath' variable created. Next, create a new variable 'taxonomyText', then save the output of the Read Text File activity to 'taxonomyText'.
* This step is where you read the contents of the taxonomy file using the 'Read Text File' activity.
The contents are stored in the 'taxonomyText' variable.
* Inside the last Assign activity 'Value to Save' property add the following expression: "Newtonsoft.
Json.JsonConvert.DeserializeObject(Of DocumentTaxonomy)(taxonomyText)" where ' taxonomyText' is the text read from the file and 'documentTaxonomy' (the most recent variable created) is the variable you created.
* In this final step, you will deserialize the JSON content from the 'taxonomyText' into a
'DocumentTaxonomy' object using the 'JsonConvert.DeserializeObject' method and assign it to the 'documentTaxonomy' variable.
Following these steps in this order will load the taxonomy from a text file into the 'documentTaxonomy' variable in UiPath.
NEW QUESTION # 113
What actions can be performed on a pipeline which is in the running state?
- A. Kill.
- B. Remove and restart.
- C. Kill, remove, and restart.
- D. Remove and kill.
Answer: A
Explanation:
When a pipeline is in the running state in UiPath AI Center, the only action that can be performed is to Kill it.
This terminates the process immediately, stopping any further processing. Actions like removing or restarting the pipeline can only be performed after the pipeline has stopped.(Source: UiPath Pipeline documentation
NEW QUESTION # 114
What are the out-of-the-box packages types available in Al Center?
- A. Pre-trained, custom training, and reviewed.
- B. Custom training, fine-tunable, and reviewed.
- C. Pre-trained. fine-tunable, and reviewed.
- D. Pre-trained. custom training, and fine-tunable.
Answer: D
Explanation:
UiPath AI Center offers three primary package types: pre-trained, custom training, and fine-tunable models.
These are essential for various use cases, from leveraging existing models to training custom ones based on specific data
NEW QUESTION # 115
Which of the following options is accepted as a Column field name in Document Manager?
- A. f1rst-name
- B. First_name123
- C. first name
- D. first_n@me
Answer: B
Explanation:
According to the UiPath documentation, the field name for a column field in Document Manager does not accept uppercase letters. It can only contain lowercase letters, numbers, underscore _ and dash -12. Therefore, the only option that meets these criteria is D. First_name123. The other options are invalid because they either contain uppercase letters, spaces, or @ symbols, which are not allowed.
References: 1: Document Understanding - Create and Configure Fields 2: Document Understanding - Create
& Configure Fields
NEW QUESTION # 116
When should a UiPath Communications Mining taxonomy be imported?
- A. As part of the "Increase coverage" phase.
- B. After pruning and reorganizing a taxonomy.
- C. Before starting the model training.
- D. When new labels must be added to the taxonomy.
Answer: C
Explanation:
In UiPath Communications Mining, importing a taxonomy should be done before starting model training. The taxonomy, which includes labels and categories, defines how the data will be classified and structured during the training process. It is essential to have a well-defined taxonomy to ensure accurate predictions and classifications. Importing the taxonomy before training allows the model to learn from it, enhancing its performance. Changes to the taxonomy can be made later, but the initial import is crucial at the start of the training phase to guide the model effectively.
(Source: UiPath Docs on Communications Mining)
NEW QUESTION # 117
What information does the comparison between two cohorts display on the Comparison page in UiPath Communications Mining?
- A. Entity count for each metadata.
- B. Total verbatim count and proportion for each label.
- C. Differences in verbatim length between Group A and Group B.
- D. Verbatim content for each label.
Answer: B
Explanation:
According to the UiPath documentation, UiPath Communications Mining is a tool that enables you to analyze text-based communications data, such as customer feedback, support tickets, or chat transcripts, using natural language processing (NLP) and machine learning (ML) techniques1. One of the features of UiPath Communications Mining is the Comparison page, which allows you to compare two cohorts of verbatims based on different criteria, such as date range, source, metadata, or label2. The Comparison page displays the following information for each cohort3:
* Total verbatim count: The number of verbatims in the cohort.
* Proportion for each label: The percentage of verbatims in the cohort that are assigned to each label. A label is a category or a topic that is relevant for the analysis, such as sentiment, intent, or issue type.
Labels can be predefined or custom-defined by the user.
* Statistical significance: The p-value that indicates whether the difference in proportions between the two cohorts is statistically significant or not. A p-value less than 0.05 means that the difference is unlikely to be due to chance.
The Comparison page also provides a visual representation of the proportions for each label using a bar chart, and allows the user to drill down into the verbatim content for each label by clicking on the bars3. Therefore, the correct answer is A.
References:
1: About Communications Mining 2: Communications Mining - Comparing Cohorts 3: Communications Mining - Comparison Page
NEW QUESTION # 118
What can the Custom Named Entity Recognition out-of-the-box model be used for?
- A. Understand sentiment in product reviews, customer surveys, social media posts, and emails.
- B. Classify text in resumes, emails, web pages, and other formats.
- C. Relate customer questions to FAQ documents and automatically pull responses from these documents.
- D. Extract and classify text in emails, letters, web pages, research papers, and call transcripts.
Answer: D
NEW QUESTION # 119
What is the correct order of recommended steps when introducing new labels into a mature taxonomy?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.
Answer:
Explanation:
NEW QUESTION # 120
Which of the following use cases is best suited for tone analysis instead of label sentiment analysis in UiPath Communications Mining?
- A. Monitoring "Quality of Service" in an operations-focused shared mailbox in a B2B organization.
- B. Analyzing customer complaints in a B2C organization.
- C. Analyzing customer satisfaction survey responses.
- D. Analyzing employee engagement survey responses.
Answer: A
Explanation:
Tone analysis is better suited for monitoring situations like "Quality of Service" in shared mailboxes, where the focus is on evaluating emotional tone in communications that may not always have clear-cut positive or negative sentiments. This contrasts with label sentiment analysis, which is better for datasets with explicit feedback (e.g., customer satisfaction surveys). In operations-focused environments, tone analysis provides more nuanced insights into service quality
NEW QUESTION # 121
What does the Label Trends table in UiPath Communications Mining show?
- A. How the top 10 senders for a given time period perform compared to the previous period and their change in rank.
- B. How the top 10 labels for a given time period perform compared to the previous period and their change in rank.
- C. How the top 10 entities for a given time period perform compared to the previous period and their change in rank.
- D. How the top 10 labels and entities for a given time period perform compared to the previous period and their change in rank.
Answer: B
Explanation:
The Label Trends table in UiPath Communications Mining shows the trend of the top 10 highest volume labels over the selected time period, as well as their percentage change and rank change compared to the previous period1. The table allows users to quickly identify which labels are increasing or decreasing in volume, and by how much, over time. The table also shows the net sentiment score for each label, which is calculated as the difference between the positive and negative sentiment probabilities for each verbatim2. The table can be filtered by data type, source, date range, and label category. Users can also sort the table by label name, volume, percentage change, rank change, or net sentiment1.
References: 1: Trends 2: Sentiment Analysis
NEW QUESTION # 122
Why might labels have bias warnings in UiPath Communications Mining, even with 100% precision?
- A. They lack training examples.
- B. They have low recall.
- C. They were trained using the "Search" option extensively.
- D. They were trained using the "Shuffle" option extensively.
Answer: A
Explanation:
Labels in UiPath Communications Mining are user-defined categories that can be applied to communications data, such as emails, chats, and calls, to identify the topics, intents, and sentiments within them1. Labels are trained using supervised learning, which means that users need to provide examples of data that belong to each label, and the system will learn from these examples to make predictions for new data2. However, not all labels are equally easy to train, and some may require more examples than others to achieve good performance. Labels that have bias warnings are those that have relatively low average precision, not enough training examples, or were labelled in a biased manner3. Precision is a measure of how accurate the predictions are for a given label, and it is calculated as the ratio of true positives (correct predictions) to the total number of predictions made for that label. A label with 100% precision means that all the predictions made for that label are correct, but it does not necessarily mean that the label is well-trained. It could be that the label has very few predictions, or that the predictions are only made on a subset of data that is similar to the training examples. This could lead to overfitting, which means that the label is too specific to the training data and does not generalize well to new or different data. Therefore, labels with 100% precision may still have bias warnings if they lack training examples, because this indicates that the label is not representative of the underlying data distribution, and may miss important variations or nuances that could affect the predictions. To improve the performance and reduce the bias of these labels, users need to provide more and diverse examples that cover the range of possible scenarios and expressions that the label should capture.
References: 1: Communications Mining Overview 2: [Creating and Training Labels] 3: Understanding and Improving Model Performance : [Precision and Recall] : [Overfitting and Underfitting] : Fixing Labelling Bias With Communications Mining
NEW QUESTION # 123
What is the benefit of making an ML Skill public?
- A. It allows access from inside of the UiPath environment.
- B. It allows access from outside of the UiPath environment.
- C. It provides additional security measures for the ML Skill.
- D. It enables automatic updates and enhancements to the ML Skill without user intervention.
Answer: B
Explanation:
Making an ML Skill public in UiPath enables it to be accessed externally from the UiPath ecosystem. This can be beneficial if the ML Skill needs to be utilized in external applications, systems, or services beyond UiPath's automation environment. Public access expands the usability of the skill, allowing integration with other systems while maintaining security through managed endpoints.
NEW QUESTION # 124
Which of the following consumes Page Units?
- A. Using ML Classifier on a 21-page document.
- B. Creation of a Document Validation Action in Action Center.
- C. Using Intelligent Form Extractor on a 5-page document with 0 successful extractions.
- D. Applying OCR on a 10-page document.
Answer: D
NEW QUESTION # 125
Which of the following data structures in a UiPath workflow allow dynamic resizing, making it suitable for scenarios where the number of elements is not predetermined?
- A. Integer
- B. List
- C. Array
- D. Tuple
Answer: B
NEW QUESTION # 126
Which of the following time periods can be selected when viewing Trends in UiPath Communications Mining?
Which of the following time periods can be selected when viewing Trends in UiPath Communications Mining?
- A. Daily, Bi-weekly, Monthly, Yearly.
- B. Daily, Bi-weekly, Quarterly, Yearly.
- C. Daily, Weekly, Monthly, Yearly.
- D. Daily, Monthly, Quarterly, Yearly.
Answer: C
NEW QUESTION # 127
What are the mandatory activities to be included in an automation workflow to allow a remote knowledge worker to pick up an action that validates the extracted data in the form of a Document Validation Action?
- A. Create Document Validation Action, Wait for Document Validation Action and Resume.
- B. Orchestration Process Activities.
- C. Document Understanding Process Activities.
- D. Present Validation Station, Wait for Document Validation Action and Resume.
Answer: A
NEW QUESTION # 128
Which of the following options is accepted as a Column field name in Document Manager?
- A. f1rst-name
- B. First_name123
- C. first name
- D. first_n@me
Answer: B
NEW QUESTION # 129
In which of the following scenarios, the ML Classifier is the only recommended classifier to be used, according to best practice?
- A. When the custom document types are not similar and file splitting is not necessary.
- B. When the custom document types are very similar and file splitting is not necessary.
- C. When the custom document types are not similar and file splitting is necessary.
- D. When the custom document types are very similar and file splitting is necessary.
Answer: B
Explanation:
The ML Classifier is a document classifier that uses a machine learning model deployed as an ML Skill in AI Center to perform document classification tasks. The ML Classifier can work by default with Invoices, Purchase Orders, Receipts, and Utility Bills, or with custom document types that are trained using the Data Manager and the Machine Learning Classifier Trainer12.
According to the best practice, the ML Classifier is the only recommended classifier to be used when the custom document types are very similar and file splitting is not necessary. This is because the ML Classifier can handle complex and ambiguous cases where the document types are hard to distinguish by rules or keywords, and can also learn from feedback and improve over time. File splitting is not necessary when the documents are single-page or have a consistent number of pages per document type3.
The other options are not correct because they are scenarios where other classifiers, such as the Keyword Based Classifier or the Intelligent Keyword Classifier, can be used in combination with the ML Classifier or instead of it. These classifiers are based on rules or keywords that can identify the document types based on their content or metadata, and can also perform file splitting if the documents are multi-page or have a variable number of pages per document type3.
References: 1: Machine Learning Classifier - UiPath Activities 2: Machine Learning Classifier Trainer - UiPath Document Understanding 3: Document Classification - UiPath Document Understanding
NEW QUESTION # 130
What are the three types of classifier trainers available in packages UiPath.lntelligentOCR.Activities and UiPath.DocumentUnderstanding.ML.Activities?
- A. Keyword Based Classifier Trainer, Intelligent Keyword Classifier Trainer, and Machine Learning Classifier Trainer.
- B. Image Based Classifier Trainer, Format Based Classifier Trainer, and Machine Learning Classifier Trainer.
- C. Intelligent Keyword Classifier Trainer, Language Based Classifier Trainer, and Image Based Classifier Trainer.
- D. Machine Learning Classifier Trainer, Language Based Classifier, and Keyword Based Classifier Trainer.
Answer: A
Explanation:
UiPath provides three types of classifier trainers to optimize document classification: Keyword Based Classifier Trainer, Intelligent Keyword Classifier Trainer, and Machine Learning Classifier Trainer.
These trainers are used to teach the system how to categorize documents based on keywords, intelligent learning patterns, or machine learning techniques for more complex classifications.(Source: UiPath Classifier Trainer documentation
NEW QUESTION # 131
Why is the Shuffle training mode important in the "Explore" phase while working with UiPath Communications Mining?
- A. Because it creates a new model version with shuffled labels and general fields and lets the user explore to understand the state of the model
- B. Because it helps create a balanced model free from labelling bias by introducing random variation into the training data.
- C. Because it helps create a balanced model by focusing on outlier labels with sufficient training examples but low confidence.
- D. Because it creates a high precision model, focusing on labels with low precision and a low number of examples.
Answer: B
Explanation:
The Shuffle training mode in the "Explore" phase of UiPath Communications Mining helps to introduce randomness into the training data. This prevents labeling bias by ensuring that the model does not overly focus on certain labels or examples, leading to a more balanced and generalized model. By shuffling the data, the model is exposed to a diverse range of examples, which enhances its ability to make accurate predictions across different labels and datasets.
(Source: UiPath Communications Mining documentation)
NEW QUESTION # 132
......
Study HIGH Quality UiPath-SAIv1 Free Study Guides and Exams Tutorials: https://www.testinsides.top/UiPath-SAIv1-dumps-review.html
New UiPath-SAIv1 Actual Exam Dumps, UiPath Practice Test: https://drive.google.com/open?id=1pwMfmSoOgunmDseImfGrGXpWP_Y6IARc