![]()
Clear your concepts with MLS-C01 Questions Before Attempting Real exam
Get professional help from our MLS-C01 Dumps PDF
The AWS Certified Machine Learning - Specialty certification exam is an excellent opportunity for professionals in the field of machine learning to demonstrate their expertise and expand their skills and knowledge on the AWS platform. With the growing demand for machine learning solutions in various industries, this certification can help professionals advance their careers and stand out in a competitive job market.
NEW QUESTION # 32
While reviewing the histogram for residuals on regression evaluation data a Machine Learning Specialist notices that the residuals do not form a zero-centered bell shape as shown What does this mean?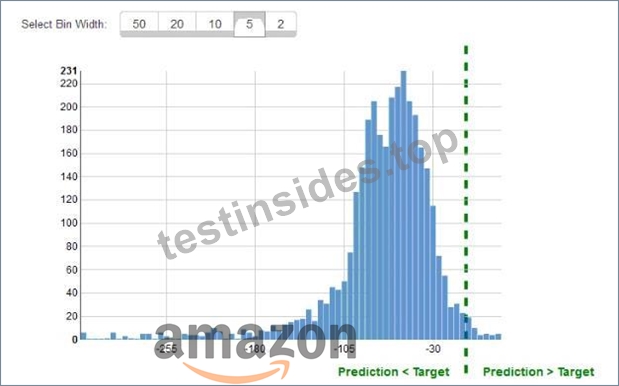
- A. The model is predicting its target values perfectly.
- B. The dataset cannot be accurately represented using the regression model
- C. The model might have prediction errors over a range of target values.
- D. There are too many variables in the model
Answer: A
NEW QUESTION # 33
A Machine Learning Specialist works for a credit card processing company and needs to predict which transactions may be fraudulent in near-real time. Specifically, the Specialist must train a model that returns the probability that a given transaction may fraudulent.
How should the Specialist frame this business problem?
- A. Streaming classification
- B. Multi-category classification
- C. Regression classification
- D. Binary classification
Answer: D
Explanation:
The business problem of predicting whether a new credit card applicant will default on a credit card payment can be framed as a binary classification problem. Binary classification is the task of predicting a discrete class label output for an example, where the class label can only take one of two possible values. In this case, the class label can be either "default" or "no default", indicating whether the applicant will or will not default on a credit card payment. A binary classification model can return the probability that a given applicant belongs to each class, and then assign the applicant to the class with the highest probability. For example, if the model predicts that an applicant has a 0.8 probability of defaulting and a 0.2 probability of not defaulting, then the model will classify the applicant as "default". Binary classification is suitable for this problem because the outcome of interest is categorical and binary, and the model needs to return the probability of each outcome.
AWS Machine Learning Specialty Exam Guide
AWS Machine Learning Training - Classification vs Regression in Machine Learning
NEW QUESTION # 34
A Data Scientist received a set of insurance records, each consisting of a record ID, the final outcome among 200 categories, and the date of the final outcome. Some partial information on claim contents is also provided, but only for a few of the 200 categories. For each outcome category, there are hundreds of records distributed over the past 3 years. The Data Scientist wants to predict how many claims to expect in each category from month to month, a few months in advance.
What type of machine learning model should be used?
- A. Classification with supervised learning of the categories for which partial information on claim contents is provided, and forecasting using claim IDs and timestamps for all other categories.
- B. Reinforcement learning using claim IDs and timestamps where the agent will identify how many claims in each category to expect from month to month.
- C. Classification month-to-month using supervised learning of the 200 categories based on claim contents.
- D. Forecasting using claim IDs and timestamps to identify how many claims in each category to expect from month to month.
Answer: D
Explanation:
Forecasting is a type of machine learning model that predicts future values of a target variable based on historical data and other features. Forecasting is suitable for problems that involve time-series data, such as the number of claims in each category from month to month. Forecasting can handle multiple categories of the target variable, as well as missing or partial information on some features. Therefore, option C is the best choice for the given problem.
Option A is incorrect because classification is a type of machine learning model that assigns a label to an input based on predefined categories. Classification is not suitable for predicting continuous or numerical values, such as the number of claims in each category from month to month. Moreover, classification requires sufficient and complete information on the features that are relevant to the target variable, which is not the case for the given problem. Option B is incorrect because reinforcement learning is a type of machine learning model that learns from its own actions and rewards in an interactive environment. Reinforcement learning is not suitable for problems that involve historical data and do not require an agent to take actions. Option D is incorrect because it combines two different types of machine learning models, which is unnecessary and inefficient. Moreover, classification is not suitable for predicting the number of claims in some categories, as explained in option A.
References:
Forecasting | AWS Solutions for Machine Learning (AI/ML) | AWS Solutions Library Time Series Forecasting Service - Amazon Forecast - Amazon Web Services Amazon Forecast: Guide to Predicting Future Outcomes - Onica Amazon Launches What-If Analyses for Machine Learning Forecasting ...
NEW QUESTION # 35
The displayed graph is from a foresting model for testing a time series.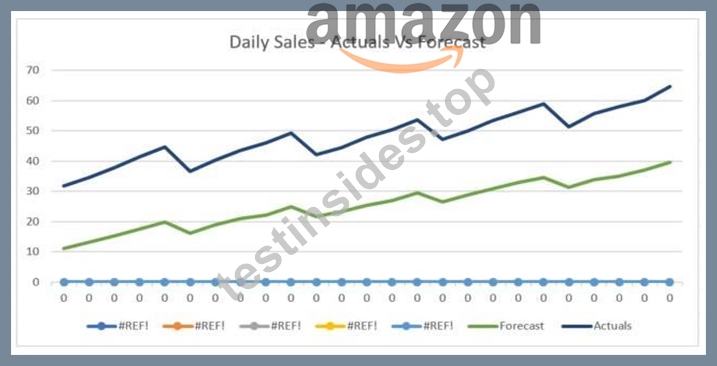
Considering the graph only, which conclusion should a Machine Learning Specialist make about the behavior of the model?
- A. The model predicts the trend well, but not the seasonality.
- B. The model does not predict the trend or the seasonality well.
- C. The model predicts both the trend and the seasonality well.
- D. The model predicts the seasonality well, but not the trend.
Answer: B
NEW QUESTION # 36
A Machine Learning Specialist must build out a process to query a dataset on Amazon S3 using Amazon Athena The dataset contains more than 800.000 records stored as plaintext CSV files Each record contains
200 columns and is approximately 1 5 MB in size Most queries will span 5 to 10 columns only How should the Machine Learning Specialist transform the dataset to minimize query runtime?
- A. Convert the records to JSON format
- B. Convert the records to GZIP CSV format
- C. Convert the records to XML format
- D. Convert the records to Apache Parquet format
Answer: D
Explanation:
* Explanation: Amazon Athena is an interactive query service that allows you to analyze data stored in Amazon S3 using standard SQL. Athena is serverless, so you only pay for the queries that you run and there is no infrastructure to manage.
* To optimize the query performance of Athena, one of the best practices is to convert the data into a columnar format, such as Apache Parquet or Apache ORC. Columnar formats store data by columns rather than by rows, which allows Athena to scan only the columns that are relevant to the query, reducing the amount of data read and improving the query speed. Columnar formats also support compression and encoding schemes that can reduce the storage space and the data scanned per query, further enhancing the performance and reducing the cost.
* In contrast, plaintext CSV files store data by rows, which means that Athena has to scan the entire row even if only a few columns are needed for the query. This increases the amount of data read and the query latency. Moreover, plaintext CSV files do not support compression or encoding, which means that they take up more storage space and incur higher query costs.
* Therefore, the Machine Learning Specialist should transform the dataset to Apache Parquet format to minimize query runtime.
References:
* Top 10 Performance Tuning Tips for Amazon Athena
* Columnar Storage Formats
Using compressions will reduce the amount of data scanned by Amazon Athena, and also reduce your S3 bucket storage. It's a Win-Win for your AWS bill. Supported formats: GZIP, LZO, SNAPPY (Parquet) and ZLIB.
NEW QUESTION # 37
A manufacturing company has a large set of labeled historical sales data The manufacturer would like to predict how many units of a particular part should be produced each quarter Which machine learning approach should be used to solve this problem?
- A. Random Cut Forest (RCF)
- B. Linear regression
- C. Logistic regression
- D. Principal component analysis (PCA)
Answer: B
Explanation:
Linear regression is a machine learning approach that can be used to solve this problem. Linear regression is a supervised learning technique that can model the relationship between one or more input variables (features) and an output variable (target). In this case, the input variables could be the historical sales data of the part, such as the quarter, the demand, the price, the inventory, etc. The output variable could be the number of units to be produced for the part. Linear regression can learn the coefficients (weights) of the input variables that best fit the output variable, and then use them to make predictions for new data. Linear regression is suitable for problems that involve continuous and numeric output variables, such as predicting house prices, stock prices, or sales volumes. References:
AWS Machine Learning Specialty Exam Guide
Linear Regression
NEW QUESTION # 38
A Machine Learning Specialist is using an Amazon SageMaker notebook instance in a private subnet of a corporate VPC. The ML Specialist has important data stored on the Amazon SageMaker notebook instance's Amazon EBS volume, and needs to take a snapshot of that EBS volume. However the ML Specialist cannot find the Amazon SageMaker notebook instance's EBS volume or Amazon EC2 instance within the VPC.
Why is the ML Specialist not seeing the instance visible in the VPC?
- A. Amazon SageMaker notebook instances are based on AWS ECS instances running within AWS service accounts.
- B. Amazon SageMaker notebook instances are based on the Amazon ECS service within customer accounts.
- C. Amazon SageMaker notebook instances are based on the EC2 instances within the customer account, but they run outside of VPCs.
- D. Amazon SageMaker notebook instances are based on EC2 instances running within AWS service accounts.
Answer: D
Explanation:
Amazon SageMaker notebook instances are fully managed environments that provide an integrated Jupyter notebook interface for data exploration, analysis, and machine learning. Amazon SageMaker notebook instances are based on EC2 instances that run within AWS service accounts, not within customer accounts.
This means that the ML Specialist cannot find the Amazon SageMaker notebook instance's EC2 instance or EBS volume within the VPC, as they are not visible or accessible to the customer. However, the ML Specialist can still take a snapshot of the EBS volume by using the Amazon SageMaker console or API. The ML Specialist can also use VPC interface endpoints to securely connect the Amazon SageMaker notebook instance to the resources within the VPC, such as Amazon S3 buckets, Amazon EFS file systems, or Amazon RDS databases
NEW QUESTION # 39
A company offers an online shopping service to its customers. The company wants to enhance the site's security by requesting additional information when customers access the site from locations that are different from their normal location. The company wants to update the process to call a machine learning (ML) model to determine when additional information should be requested.
The company has several terabytes of data from its existing ecommerce web servers containing the source IP addresses for each request made to the web server. For authenticated requests, the records also contain the login name of the requesting user.
Which approach should an ML specialist take to implement the new security feature in the web application?
- A. Use Amazon SageMaker Ground Truth to label each record as either a successful or failed access attempt. Use Amazon SageMaker to train a binary classification model using the IP Insights algorithm.
- B. Use Amazon SageMaker to train a model using the Object2Vec algorithm. Schedule updates and retraining of the model using new log data nightly.
- C. Use Amazon SageMaker to train a model using the IP Insights algorithm. Schedule updates and retraining of the model using new log data nightly.
- D. Use Amazon SageMaker Ground Truth to label each record as either a successful or failed access attempt. Use Amazon SageMaker to train a binary classification model using the factorization machines (FM) algorithm.
Answer: C
Explanation:
Explanation
The IP Insights algorithm is designed to capture associations between entities and IP addresses, and can be used to identify anomalous IP usage patterns. The algorithm can learn from historical data that contains pairs of entities and IP addresses, and can return a score that indicates how likely the pair is to occur. The company can use this algorithm to train a model that can detect when a customer is accessing the site from a different location than usual, and request additional information accordingly. The company can also schedule updates and retraining of the model using new log data nightly to keep the model up to date with the latest IP usage patterns.
The other options are not suitable for this use case because:
Option A: The factorization machines (FM) algorithm is a general-purpose supervised learning algorithm that can be used for both classification and regression tasks. However, it is not optimized for capturing associations between entities and IP addresses, and would require labeling each record as either a successful or failed access attempt, which is a costly and time-consuming process.
Option C: The IP Insights algorithm is a good choice for this use case, but it does not require labeling each record as either a successful or failed access attempt. The algorithm is unsupervised and can learn from the historical data without labels. Labeling the data would be unnecessary and wasteful.
Option D: The Object2Vec algorithm is a general-purpose neural embedding algorithm that can learn low-dimensional dense embeddings of high-dimensional objects. However, it is not designed to capture associations between entities and IP addresses, and would require a different input format than the one provided by the company. The Object2Vec algorithm expects pairs of objects and their relationship labels or scores as inputs, while the company has data containing the source IP addresses and the login names of the requesting users.
References:
IP Insights - Amazon SageMaker
Factorization Machines Algorithm - Amazon SageMaker
Object2Vec Algorithm - Amazon SageMaker
NEW QUESTION # 40
A financial company is trying to detect credit card fraud. The company observed that, on average, 2% of credit card transactions were fraudulent. A data scientist trained a classifier on a year's worth of credit card transactions data. The model needs to identify the fraudulent transactions (positives) from the regular ones (negatives). The company's goal is to accurately capture as many positives as possible.
Which metrics should the data scientist use to optimize the model? (Choose two.)
- A. True positive rate
- B. Area under the precision-recall curve
- C. Specificity
- D. False positive rate
- E. Accuracy
Answer: A,B
Explanation:
Explanation
The data scientist should use the area under the precision-recall curve and the true positive rate to optimize the model. These metrics are suitable for imbalanced classification problems, such as credit card fraud detection, where the positive class (fraudulent transactions) is much rarer than the negative class (non-fraudulent transactions).
The area under the precision-recall curve (AUPRC) is a measure of how well the model can identify the positive class among all the predicted positives. Precision is the fraction of predicted positives that are actually positive, and recall is the fraction of actual positives that are correctly predicted. A higher AUPRC means that the model can achieve a higher precision with a higher recall, which is desirable for fraud detection.
The true positive rate (TPR) is another name for recall. It is also known as sensitivity or hit rate. It measures the proportion of actual positives that are correctly identified by the model. A higher TPR means that the model can capture more positives, which is the company's goal.
References:
Metrics for Imbalanced Classification in Python - Machine Learning Mastery Precision-Recall - scikit-learn
NEW QUESTION # 41
A machine learning (ML) specialist wants to secure calls to the Amazon SageMaker Service API. The specialist has configured Amazon VPC with a VPC interface endpoint for the Amazon SageMaker Service API and is attempting to secure traffic from specific sets of instances and IAM users. The VPC is configured with a single public subnet.
Which combination of steps should the ML specialist take to secure the traffic? (Choose two.)
- A. Add a SageMaker Runtime VPC endpoint interface to the VPC.
- B. Modify the users' IAM policy to allow access to Amazon SageMaker Service API calls only.
- C. Modify the security group on the endpoint network interface to restrict access to the instances.
- D. Add a VPC endpoint policy to allow access to the IAM users.
- E. Modify the ACL on the endpoint network interface to restrict access to the instances.
Answer: C,D
Explanation:
Explanation/Reference: https://aws.amazon.com/blogs/machine-learning/private-package-installation-in-amazon- sagemaker-running-in-internet-free-mode/
NEW QUESTION # 42
A financial services company is building a robust serverless data lake on Amazon S3. The data lake should be flexible and meet the following requirements:
* Support querying old and new data on Amazon S3 through Amazon Athena and Amazon Redshift Spectrum.
* Support event-driven ETL pipelines.
* Provide a quick and easy way to understand metadata.
Which approach meets trfese requirements?
- A. Use an AWS Glue crawler to crawl S3 data, an AWS Lambda function to trigger an AWS Glue ETL job, and an AWS Glue Data catalog to search and discover metadata.
- B. Use an AWS Glue crawler to crawl S3 data, an Amazon CloudWatch alarm to trigger an AWS Batch job, and an AWS Glue Data Catalog to search and discover metadata.
- C. Use an AWS Glue crawler to crawl S3 data, an Amazon CloudWatch alarm to trigger an AWS Glue ETL job, and an external Apache Hive metastore to search and discover metadata.
- D. Use an AWS Glue crawler to crawl S3 data, an AWS Lambda function to trigger an AWS Batch job, and an external Apache Hive metastore to search and discover metadata.
Answer: A
Explanation:
To build a robust serverless data lake on Amazon S3 that meets the requirements, the financial services company should use the following AWS services:
* AWS Glue crawler: This is a service that connects to a data store, progresses through a prioritized list of classifiers to determine the schema for the data, and then creates metadata tables in the AWS Glue Data Catalog1. The company can use an AWS Glue crawler to crawl the S3 data and infer the schema, format, and partition structure of the data. The crawler can also detect schema changes and update the metadata tables accordingly. This enables the company to support querying old and new data on Amazon S3 through Amazon Athena and Amazon Redshift Spectrum, which are serverless interactive query services that use the AWS Glue Data Catalog as a central location for storing and retrieving table metadata23.
* AWS Lambda function: This is a service that lets you run code without provisioning or managing servers. You pay only for the compute time you consume - there is no charge when your code is not running. You can also use AWS Lambda to create event-driven ETL pipelines, by triggering other AWS services based on events such as object creation or deletion in S3 buckets4. The company can use an AWS Lambda function to trigger an AWS Glue ETL job, which is a serverless way to extract, transform, and load data for analytics. The AWS Glue ETL job can perform various data processing tasks, such as converting data formats, filtering, aggregating, joining, and more.
* AWS Glue Data Catalog: This is a managed service that acts as a central metadata repository for data assets across AWS and on-premises data sources. The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos, and use that metadata to query and transform the data. The company can use the AWS Glue Data Catalog to search and discover metadata, such as table definitions, schemas, and partitions. The AWS Glue Data Catalog also integrates with Amazon Athena, Amazon Redshift Spectrum, Amazon EMR, and AWS Glue ETL jobs, providing a consistent view of the data across different query and analysis services.
References:
* 1: What Is a Crawler? - AWS Glue
* 2: What Is Amazon Athena? - Amazon Athena
* 3: Amazon Redshift Spectrum - Amazon Redshift
* 4: What is AWS Lambda? - AWS Lambda
* : AWS Glue ETL Jobs - AWS Glue
* : What Is the AWS Glue Data Catalog? - AWS Glue
NEW QUESTION # 43
A data scientist is using the Amazon SageMaker Neural Topic Model (NTM) algorithm to build a model that recommends tags from blog posts. The raw blog post data is stored in an Amazon S3 bucket in JSON format.
During model evaluation, the data scientist discovered that the model recommends certain stopwords such as
"a," "an," and "the" as tags to certain blog posts, along with a few rare words that are present only in certain blog entries. After a few iterations of tag review with the content team, the data scientist notices that the rare words are unusual but feasible. The data scientist also must ensure that the tag recommendations of the generated model do not include the stopwords.
What should the data scientist do to meet these requirements?
- A. Use the SageMaker built-in Object Detection algorithm instead of the NTM algorithm for the training job to process the blog post data.
- B. Remove the stop words from the blog post data by using the Count Vectorizer function in the scikit-learn library. Replace the blog post data in the S3 bucket with the results of the vectorizer.
- C. Run the SageMaker built-in principal component analysis (PCA) algorithm with the blog post data from the S3 bucket as the data source. Replace the blog post data in the S3 bucket with the results of the training job.
- D. Use the Amazon Comprehend entity recognition API operations. Remove the detected words from the blog post data. Replace the blog post data source in the S3 bucket.
Answer: B
Explanation:
Explanation
The data scientist should remove the stop words from the blog post data by using the Count Vectorizer function in the scikit-learn library, and replace the blog post data in the S3 bucket with the results of the vectorizer. This is because:
The Count Vectorizer function is a tool that can convert a collection of text documents to a matrix of token counts 1. It also enables the pre-processing of text data prior to generating the vector representation, such as removing accents, converting to lowercase, and filtering out stop words 1. By using this function, the data scientist can remove the stop words such as "a," "an," and "the" from the blog post data, and obtain a numerical representation of the text that can be used as input for the NTM algorithm.
The NTM algorithm is a neural network-based topic modeling technique that can learn latent topics from a corpus of documents 2. It can be used to recommend tags from blog posts by finding the most probable topics for each document, and ranking the words associated with each topic 3. However, the NTM algorithm does not perform any text pre-processing by itself, so it relies on the quality of the input data. Therefore, the data scientist should replace the blog post data in the S3 bucket with the results of the vectorizer, to ensure that the NTM algorithm does not include the stop words in the tag recommendations.
The other options are not suitable for the following reasons:
Option A is not relevant because the Amazon Comprehend entity recognition API operations are used to detect and extract named entities from text, such as people, places, organizations, dates, etc4. This is not the same as removing stop words, which are common words that do not carry much meaning or information. Moreover, removing the detected entities from the blog post data may reduce the quality and diversity of the tag recommendations, as some entities may be relevant and useful as tags.
Option B is not optimal because the SageMaker built-in principal component analysis (PCA) algorithm is used to reduce the dimensionality of a dataset by finding the most important features that capture the maximum amount of variance in the data 5. This is not the same as removing stop words, which are words that have low variance and high frequency in the data. Moreover, replacing the blog post data in the S3 bucket with the results of the PCA algorithm may not be compatible with the input format expected by the NTM algorithm, which requires a bag-of-words representation of the text 2.
Option C is not suitable because the SageMaker built-in Object Detection algorithm is used to detect and localize objects in images 6. This is not related to the task of recommending tags from blog posts, which are text documents. Moreover, using the Object Detection algorithm instead of the NTM algorithm would require a different type of input data (images instead of text), and a different type of output data (bounding boxes and labels instead of topics and words).
References:
Neural Topic Model (NTM) Algorithm
Introduction to the Amazon SageMaker Neural Topic Model
Amazon Comprehend - Entity Recognition
sklearn.feature_extraction.text.CountVectorizer
Principal Component Analysis (PCA) Algorithm
Object Detection Algorithm
NEW QUESTION # 44
A company has raw user and transaction data stored in AmazonS3 a MySQL database, and Amazon RedShift A Data Scientist needs to perform an analysis by joining the three datasets from Amazon S3, MySQL, and Amazon RedShift, and then calculating the average-of a few selected columns from the joined data Which AWS service should the Data Scientist use?
- A. Amazon Redshift Spectrum
- B. Amazon Athena
- C. AWS Glue
- D. Amazon QuickSight
Answer: B
Explanation:
Explanation
Amazon Athena is a serverless interactive query service that can analyze data in Amazon S3 using standard SQL. Amazon Athena can also query data from other sources, such as MySQL and Amazon Redshift, by using federated queries. Federated queries allow Amazon Athena to run SQL queries across data sources, such as relational and non-relational databases, data warehouses, and data lakes. By using Amazon Athena, the Data Scientist can perform an analysis by joining the three datasets from Amazon S3, MySQL, and Amazon Redshift, and then calculating the average of a few selected columns from the joined data. Amazon Athena can also integrate with other AWS services, such as AWS Glue and Amazon QuickSight, to provide additional features, such as data cataloging and visualization.
References:
What is Amazon Athena? - Amazon Athena
Federated Query Overview - Amazon Athena
Querying Data from Amazon S3 - Amazon Athena
Querying Data from MySQL - Amazon Athena
[Querying Data from Amazon Redshift - Amazon Athena]
NEW QUESTION # 45
A Machine Learning Specialist is planning to create a long-running Amazon EMR cluster. The EMR cluster will have 1 master node, 10 core nodes, and 20 task nodes. To save on costs, the Specialist will use Spot Instances in the EMR cluster.
Which nodes should the Specialist launch on Spot Instances?
- A. Master node
- B. Any of the task nodes
- C. Any of the core nodes
- D. Both core and task nodes
Answer: A
NEW QUESTION # 46
A company needs to quickly make sense of a large amount of data and gain insight from it. The data is in different formats, the schemas change frequently, and new data sources are added regularly. The company wants to use AWS services to explore multiple data sources, suggest schemas, and enrich and transform the dat a. The solution should require the least possible coding effort for the data flows and the least possible infrastructure management.
Which combination of AWS services will meet these requirements?
- A. Amazon Kinesis Data Analytics for data ingestion
Amazon EMR for data discovery, enrichment, and transformation
Amazon Redshift for querying and analyzing the results in Amazon S3 - B. AWS Data Pipeline for data transfer
AWS Step Functions for orchestrating AWS Lambda jobs for data discovery, enrichment, and transformation Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL - C. AWS Glue for data discovery, enrichment, and transformation
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL Amazon QuickSight for reporting and getting insights - D. Amazon EMR for data discovery, enrichment, and transformation
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL Amazon QuickSight for reporting and getting insights
Answer: D
Explanation:
Amazon QuickSight for reporting and getting insights
NEW QUESTION # 47
A company wants to create a data repository in the AWS Cloud for machine learning (ML) projects. The company wants to use AWS to perform complete ML lifecycles and wants to use Amazon S3 for the data storage. All of the company's data currently resides on premises and is 40 in size.
The company wants a solution that can transfer and automatically update data between the on-premises object storage and Amazon S3. The solution must support encryption, scheduling, monitoring, and data integrity validation.
Which solution meets these requirements?
- A. Use the S3 sync command to compare the source S3 bucket and the destination S3 bucket. Determine which source files do not exist in the destination S3 bucket and which source files were modified.
- B. Use AWS Transfer for FTPS to transfer the files from the on-premises storage to Amazon S3.
- C. Use S3 Batch Operations to pull data periodically from the on-premises storage. Enable S3 Versioning on the S3 bucket to protect against accidental overwrites.
- D. Use AWS DataSync to make an initial copy of the entire dataset. Schedule subsequent incremental transfers of changing data until the final cutover from on premises to AWS.
Answer: D
Explanation:
Explanation
The best solution to meet the requirements of the company is to use AWS DataSync to make an initial copy of the entire dataset, and schedule subsequent incremental transfers of changing data until the final cutover from on premises to AWS. This is because:
AWS DataSync is an online data movement and discovery service that simplifies data migration and helps you quickly, easily, and securely transfer your file or object data to, from, and between AWS storage services 1. AWS DataSync can copy data between on-premises object storage and Amazon S3, and also supports encryption, scheduling, monitoring, and data integrity validation 1.
AWS DataSync can make an initial copy of the entire dataset by using a DataSync agent, which is a software appliance that connects to your on-premises storage and manages the data transfer to AWS 2. The DataSync agent can be deployed as a virtual machine (VM) on your existing hypervisor, or as an Amazon EC2 instance in your AWS account 2.
AWS DataSync can schedule subsequent incremental transfers of changing data by using a task, which is a configuration that specifies the source and destination locations, the options for the transfer, and the schedule for the transfer 3. You can create a task to run once or on a recurring schedule, and you can also use filters to include or exclude specific files or objects based on their names or prefixes 3.
AWS DataSync can perform the final cutover from on premises to AWS by using a sync task, which is a type of task that synchronizes the data in the source and destination locations 4. A sync task transfers only the data that has changed or that doesn't exist in the destination, and also deletes any files or objects from the destination that were deleted from the source since the last sync 4.
Therefore, by using AWS DataSync, the company can create a data repository in the AWS Cloud for machine learning projects, and use Amazon S3 for the data storage, while meeting the requirements of encryption, scheduling, monitoring, and data integrity validation.
References:
Data Transfer Service - AWS DataSync
Deploying a DataSync Agent
Creating a Task
Syncing Data with AWS DataSync
NEW QUESTION # 48
A machine learning specialist is preparing data for training on Amazon SageMaker. The specialist is using one of the SageMaker built-in algorithms for the training. The dataset is stored in .CSV format and is transformed into a numpy.array, which appears to be negatively affecting the speed of the training.
What should the specialist do to optimize the data for training on SageMaker?
- A. Use AWS Glue to compress the data into the Apache Parquet format.
- B. Use the SageMaker batch transform feature to transform the training data into a DataFrame.
- C. Transform the dataset into the RecordIO protobuf format.
- D. Use the SageMaker hyperparameter optimization feature to automatically optimize the data.
Answer: C
Explanation:
SageMaker built-in algorithms are optimized to use RecordIO protobuf data format, which significantly improves data transfer and training speeds compared to numpy arrays.
From AWS documentation:
"The Amazon SageMaker built-in algorithms work best with data in the RecordIO protobuf format, which allows for faster data streaming and lower latency during training."
- AWS SageMaker Algorithm documentation
NEW QUESTION # 49
A company uses camera images of the tops of items displayed on store shelves to determine which items were removed and which ones still remain. After several hours of data labeling, the company has a total of
1,000 hand-labeled images covering 10 distinct items. The training results were poor.
Which machine learning approach fulfills the company's long-term needs?
- A. Reduce the number of distinct items from 10 to 2, build the model, and iterate
- B. Convert the images to grayscale and retrain the model
- C. Augment training data for each item using image variants like inversions and translations, build the model,
- D. Attach different colored labels to each item, take the images again, and build the model
Answer: B
Explanation:
and iterate.
NEW QUESTION # 50
A company is observing low accuracy while training on the default built-in image classification algorithm in Amazon SageMaker. The Data Science team wants to use an Inception neural network architecture instead of a ResNet architecture.
Which of the following will accomplish this? (Select TWO.)
- A. Download and apt-get install the inception network code into an Amazon EC2 instance and use this instance as a Jupyter notebook in Amazon SageMaker.
- B. Bundle a Docker container with TensorFlow Estimator loaded with an Inception network and use this for model training.
- C. Create a support case with the SageMaker team to change the default image classification algorithm to Inception.
- D. Customize the built-in image classification algorithm to use Inception and use this for model training.
- E. Use custom code in Amazon SageMaker with TensorFlow Estimator to load the model with an Inception network and use this for model training.
Answer: D,E
NEW QUESTION # 51
A gaming company has launched an online game where people can start playing for free but they need to pay if they choose to use certain features The company needs to build an automated system to predict whether or not a new user will become a paid user within 1 year The company has gathered a labeled dataset from 1 million users The training dataset consists of 1.000 positive samples (from users who ended up paying within 1 year) and
999.000 negative samples (from users who did not use any paid features) Each data sample consists of 200 features including user age, device, location, and play patterns Using this dataset for training, the Data Science team trained a random forest model that converged with over
99% accuracy on the training set However, the prediction results on a test dataset were not satisfactory.
Which of the following approaches should the Data Science team take to mitigate this issue? (Select TWO.)
- A. Add more deep trees to the random forest to enable the model to learn more features.
- B. Generate more positive samples by duplicating the positive samples and adding a small amount of noise to the duplicated data.
- C. Change the cost function so that false negatives have a higher impact on the cost value than false positives
- D. indicate a copy of the samples in the test database in the training dataset
- E. Change the cost function so that false positives have a higher impact on the cost value than false negatives
Answer: B,C
Explanation:
Explanation
The Data Science team is facing a problem of imbalanced data, where the positive class (paid users) is much less frequent than the negative class (non-paid users). This can cause the random forest model to be biased towards the majority class and have poor performance on the minority class. To mitigate this issue, the Data Science team can try the following approaches:
C: Generate more positive samples by duplicating the positive samples and adding a small amount of noise to the duplicated data. This is a technique called data augmentation, which can help increase the size and diversity of the training data for the minority class. This can help the random forest model learn more features and patterns from the positive class and reduce the imbalance ratio.
D: Change the cost function so that false negatives have a higher impact on the cost value than false positives. This is a technique called cost-sensitive learning, which can assign different weights or costs to different classes or errors. By assigning a higher cost to false negatives (predicting non-paid when the user is actually paid), the random forest model can be more sensitive to the minority class and try to minimize the misclassification of the positive class.
References:
Bagging and Random Forest for Imbalanced Classification
Surviving in a Random Forest with Imbalanced Datasets
machine learning - random forest for imbalanced data? - Cross Validated Biased Random Forest For Dealing With the Class Imbalance Problem
NEW QUESTION # 52
A Machine Learning Specialist is creating a new natural language processing application that processes a dataset comprised of 1 million sentences The aim is to then run Word2Vec to generate embeddings of the sentences and enable different types of predictions - Here is an example from the dataset
"The quck BROWN FOX jumps over the lazy dog "
Which of the following are the operations the Specialist needs to perform to correctly sanitize and prepare the data in a repeatable manner? (Select THREE)
- A. Normalize all words by making the sentence lowercase
- B. Perform part-of-speech tagging and keep the action verb and the nouns only
- C. One-hot encode all words in the sentence
- D. Remove stop words using an English stopword dictionary.
- E. Correct the typography on "quck" to "quick."
- F. Tokenize the sentence into words.
Answer: A,D,F
Explanation:
To prepare the data for Word2Vec, the Specialist needs to perform some preprocessing steps that can help reduce the noise and complexity of the data, as well as improve the quality of the embeddings. Some of the common preprocessing steps for Word2Vec are:
* Normalizing all words by making the sentence lowercase: This can help reduce the vocabulary size and treat words with different capitalizations as the same word. For example, "Fox" and "fox" should be considered as the same word, not two different words.
* Removing stop words using an English stopword dictionary: Stop words are words that are very common and do not carry much semantic meaning, such as "the", "a", "and", etc. Removing them can help focus on the words that are more relevant and informative for the task.
* Tokenizing the sentence into words: Tokenization is the process of splitting a sentence into smaller units, such as words or subwords. This is necessary for Word2Vec, as it operates on the word level and requires a list of words as input.
The other options are not necessary or appropriate for Word2Vec:
* Performing part-of-speech tagging and keeping the action verb and the nouns only: Part-of-speech tagging is the process of assigning a grammatical category to each word, such as noun, verb, adjective, etc. This can be useful for some natural language processing tasks, but not for Word2Vec, as it can lose some important information and context by discarding other words.
* Correcting the typography on "quck" to "quick": Typo correction can be helpful for some tasks, but not for Word2Vec, as it can introduce errors and inconsistencies in the data. For example, if the typo is intentional or part of a dialect, correcting it can change the meaning or style of the sentence. Moreover, Word2Vec can learn to handle typos and variations in spelling by learning similar embeddings for them.
* One-hot encoding all words in the sentence: One-hot encoding is a way of representing words as vectors of 0s and 1s, where only one element is 1 and the rest are 0. The index of the 1 element corresponds to the word's position in the vocabulary. For example, if the vocabulary is ["cat", "dog",
"fox"], then "cat" can be encoded as [1, 0, 0], "dog" as [0, 1, 0], and "fox" as [0, 0, 1]. This can be useful for some machine learning models, but not for Word2Vec, as it does not capture the semantic similarity and relationship between words. Word2Vec aims to learn dense and low-dimensional embeddings for words, where similar words have similar vectors.
NEW QUESTION # 53
A Machine Learning Specialist prepared the following graph displaying the results of k-means for k = [1:10]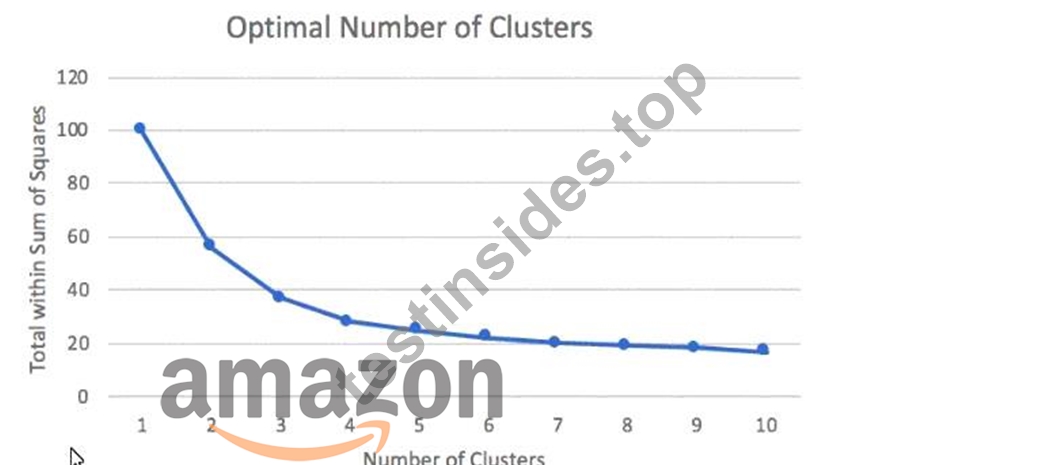
Considering the graph, what is a reasonable selection for the optimal choice of k?
- A. 0
- B. 1
- C. 2
- D. 3
Answer: B
NEW QUESTION # 54
......
Achieve the MLS-C01 Exam Best Results with Help from Amazon Certified Experts: https://www.testinsides.top/MLS-C01-dumps-review.html
Give You Free Regular Updates on MLS-C01 Exam Questions: https://drive.google.com/open?id=1cFtLnCTqiYQbq9hRaHJbs_q_UaOaow6M